Subscribe to Our Newsletter
Sign up for our bi-weekly newsletter to learn about computer vision trends and insights.
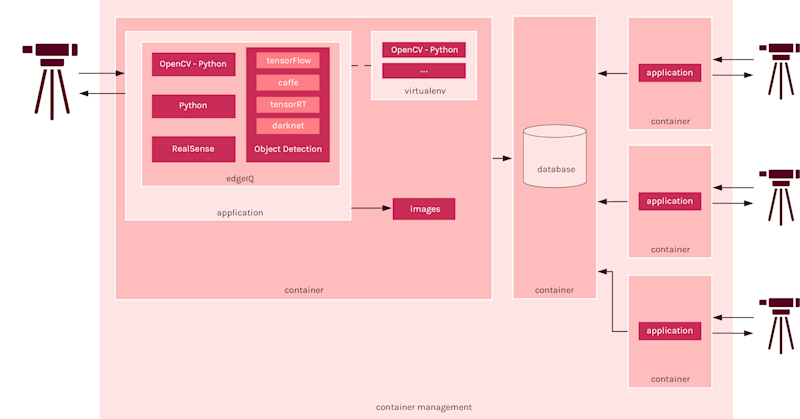
Computer Vision on the Edge
by

Lila Mullany
Subscribe to Our Newsletter
Sign up for our bi-weekly newsletter to learn about computer vision trends and insights.
Lila Mullany
